Pythonで簡単に画像スクレイピング チュートリアル

こんにちは。
扉です。
この記事では基本的な文法を知っていれば、簡単に初心者でもpythonで画像スクレイピングできるってことを知ってもらえたらと思います。
最初はこの記事のコードを書き写して学んで、その次は自分でサイトを見つけてスクレイピングしてみてください。そうすればスクレイピング技術が身についていきます。
環境
windows
python3.6.4(Anaconda)
あるメーカーHPの商品画像をダウンロードする
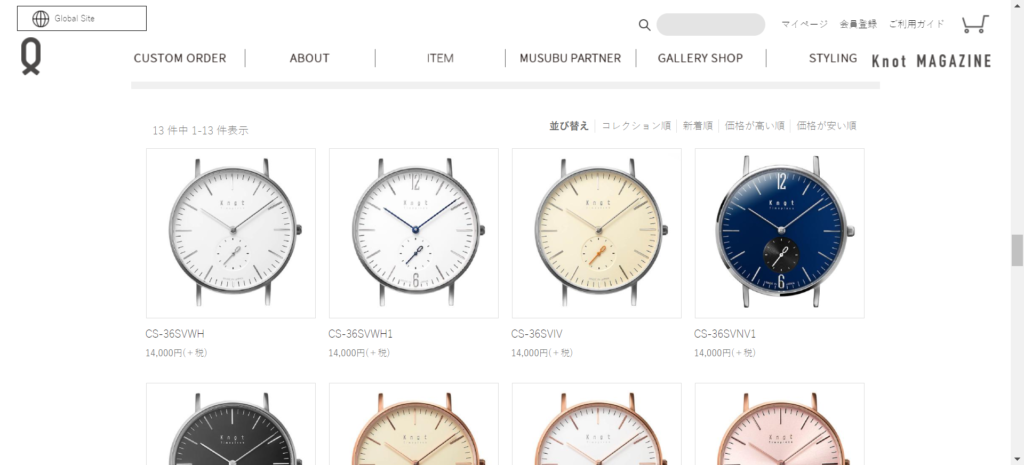
今回はこの腕時計メーカーの商品である腕時計の画像を自動取得したいと思います。
このHPの腕時計の画像に名前をつけて保存していきます。
まず全体のコードを。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
#coding:UTF-8 import requests from bs4 import BeautifulSoup from urllib.parse import urljoin import urllib.request import os folder= 'test' os.makedirs(folder, exist_ok=True) url_list= [] title_list=[] def get_hp(url): res = requests.get(url) res.raise_for_status() #エラーならここで例外を発生させる return res.text def pickup_tag(url): soup = BeautifulSoup(get_hp(url), 'html.parser') get_tag = soup.select("img.thumbnail") #get_tag = list(dict.fromkeys(get_tag)) if get_tag is None: print("見つかりません") quit() return get_tag print("element :", len(pickup_tag("http://knot-designs.com/fs/knot/c/smallsecond"))) def get_photo_url(url): for temp in pickup_tag(url): url_fact = temp.get("src") yield url_fact url_list.append(url_fact) def get_title(url): for i in get_photo_url(url): pass soup = BeautifulSoup(get_hp(url), 'html.parser') get_title_tag = soup.select('h2 a') if get_title_tag is None: print('見つかりません') quit() for sample in get_title_tag: element_titile = sample.get_text() yield element_titile title_list.append(element_titile) for i in get_title("http://knot-designs.com/fs/knot/c/smallsecond"): pass print(title_list) print(url_list) for n in range(len(url_list)): image_url = "http://knot-designs.com" + url_list[n] print('画像をダウンロード中 {}...'.format(image_url)) res = requests.get(image_url) res.raise_for_status() image_file = open(os.path.join(folder, os.path.basename(title_list[n]+'.jpg')), 'wb') for chunk in res.iter_content(100000): image_file.write(chunk) image_file.close() |
準備
先頭にあるこちらから説明。
|
1 2 3 4 |
folder= 'test' os.makedirs(folder, exist_ok=True) url_list= [] title_list=[] |
folder は画像が保存されるディレクトリ名。
os.makedirsでカレントディレクトリにtestというディレクトリが作成されます。
既にその名前のディレクトリがあればそのまま実行されます。
その下に2つリストが並んでいます。これは後に使うので、初めに作成しておきました。
get_hp( ) 関数
|
1 2 3 4 |
def get_hp(url): res = requests.get(url) res.raise_for_status() #エラーならここで例外を発生させる return res.text |
そしてレスポンスに対して.textとすることでテキスト形式で取得しています。
pickup_tag( ) 関数
|
1 2 3 4 5 6 7 8 |
def pickup_tag(url): soup = BeautifulSoup(get_hp(url), 'html.parser') get_tag = soup.select("img.thumbnail") if get_tag is None: print("見つかりません") quit() return get_tag print("element :", len(pickup_tag("http://knot-designs.com/fs/knot/c/smallsecond"))) |
soupの第一引数には、get_hp() の戻り値である res.text が入ります。
get_tag では画像のURLを抜き出しをしています。
thumbnail というクラスを指定し、その指定したクラス内の imgタグを全て抜き取るというコード。
少し難しいと思いますが、ここは抜き取りたいページの HTML を自分で読むしかないです。抜き出したいページに行き、右クリックして「検証」(Ctrl + Shift + I) を押すと、DevTools が開かれるので自分の抜き出したいところを確認しましょう。
スクレイピングは HTML, CSS の知識が少し必要となってくるので Progate などで学んでおくのがオススメ。ぼくも Progate で学びました。
抜き取るメソッドはいくつかあり find, find_all, select など何を使えばいいかわからないと思いますが、ググれば沢山出てくるのでprint文で確かめてトライアンドエラーを繰り返すのがいいと思います(まだぼくもググりながらやってます)。
【実践】 画像のタグ抜き取り方
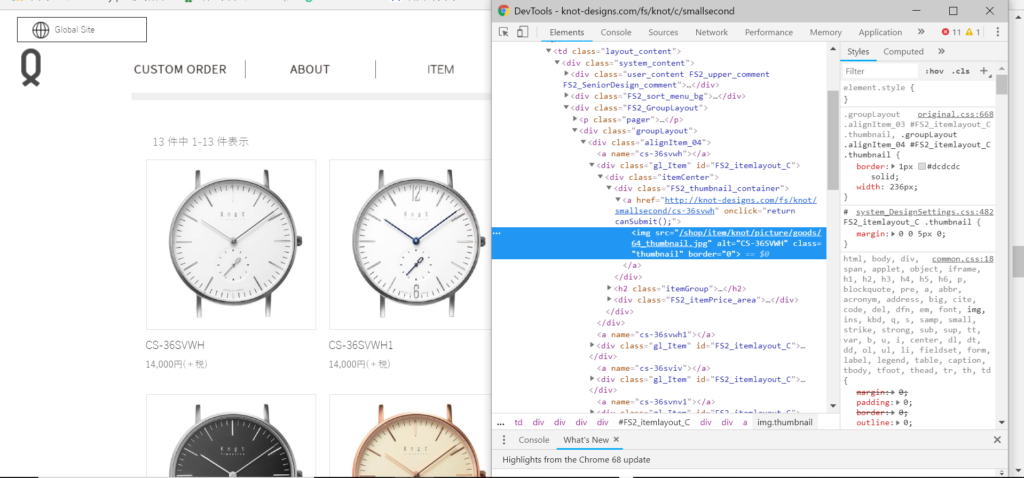
画像の上で右クリックで検証を押すと、Devtools が出てきます。取得したい画像の詳細を見るとaタグの中にimgタグがあり class=” thumbnail ” を持っています。このことから img.thumbnail で指定すれよさそうだということが分かります。
試しにprint( pickup_tag(“http://knot-designs.com/fs/knot/c/smallsecond”) )と書いて、出力してみると
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
> python main.py [<img class="thumbnail" src="/shop/item/knot/picture/goods/64_thumbnail.jpg" alt="CS-36SVWH" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/65_thumbnail.jpg" alt="CS-36SVWH1" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/61_thumbnail.jpg" alt="CS-36SVIV" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/629_thumbnail.jpg" alt="CS-36SVNV1" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/59_thumbnail.jpg" alt="CS-36SVBK" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/57_thumbnail.jpg" alt="CS-36RGIV" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/58_thumbnail.jpg" alt="CS-36RGWH" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/422_thumbnail.jpg" alt="CS-36RGRG" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/67_thumbnail.jpg" alt="CS-36YGSV" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/66_thumbnail.jpg" alt="CS-36YGBK" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/632_thumbnail.jpg" alt="CS-36BKMT" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/968_thumbnail.jpg" alt="CS-36BKWH" border="0" />, <img class="thumbnail" src="/shop/item/knot/picture/goods/965_thumbnail.jpg" alt="CS/OG-36SVSVYG" border="0" />] element = 13 |
このように get_tag はリストとなり、class=”thumbnail”のimgタグが抜き取れていることが分かります。このようにprintでちゃんと抜き取れているかその都度確認するようにしてください。
そして len( ) メソッドでリストの要素数を確認すると element = 13 となっています。
HP を見ると左上に商品数が 13 件と表示されており、過不足なくimgタグを抜き取れたことが確認できます。
やったね!!!
get_photo_url( ) 関数
|
1 2 3 4 5 |
def get_photo_url(url): for temp in pickup_tag(url): url_fact = temp.get("src") yield url_fact url_list.append(url_fact) |
pickup_tag()の戻り値はプロンプト上に先ほど出力されたリストです。それをforループで1つずつ要素を取り出し、temp.get(” src “)で src=” ここ!!! ” だけを入手しています。
そしてそれらを url_list = [ ] に append しています。
これをまた print で確認すると、
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
> python main.py /shop/item/knot/picture/goods/64_thumbnail.jpg /shop/item/knot/picture/goods/65_thumbnail.jpg /shop/item/knot/picture/goods/61_thumbnail.jpg /shop/item/knot/picture/goods/629_thumbnail.jpg /shop/item/knot/picture/goods/59_thumbnail.jpg /shop/item/knot/picture/goods/57_thumbnail.jpg /shop/item/knot/picture/goods/58_thumbnail.jpg /shop/item/knot/picture/goods/422_thumbnail.jpg /shop/item/knot/picture/goods/67_thumbnail.jpg /shop/item/knot/picture/goods/66_thumbnail.jpg /shop/item/knot/picture/goods/632_thumbnail.jpg /shop/item/knot/picture/goods/968_thumbnail.jpg /shop/item/knot/picture/goods/965_thumbnail.jpg |
get_title( ) 関数
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
def get_title(url): for i in get_photo_url(url): #url_listの作成 pass soup = BeautifulSoup(get_hp(url), 'html.parser') get_title_tag = soup.select('h2 a') if get_title_tag is None: print('見つかりません') quit() for sample in get_title_tag: element_titile = sample.get_text() yield element_titile title_list.append(element_titile) for i in get_title("http://knot-designs.com/fs/knot/c/smallsecond"): pass print(title_list) print(url_list) |
まず商品名のあるタグの取得。
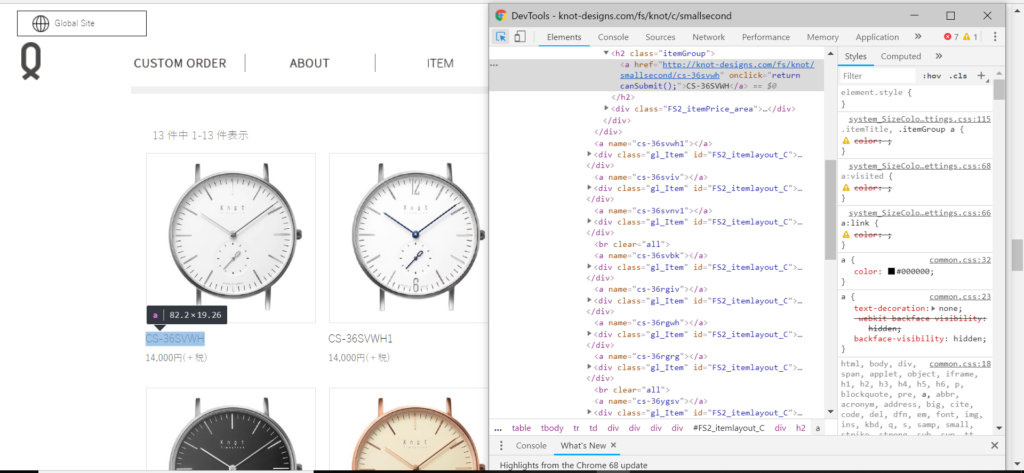
また右クリックで検証(Ctrl + Shift + I) をすると、h2 のaタグのテキストに商品の名前があります。
だから select(‘ h2 a ‘) とします。
get_title_tag を print してみると以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
> pyton main.py [<a href="http://knot-designs.com/fs/knot/smallsecond/cs-36svwh">CS-36SVWH</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36svwh1">CS-36SVWH1</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36sviv">CS-36SVIV</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36svnv1">CS-36SVNV1</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36svbk">CS-36SVBK</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36rgiv">CS-36RGIV</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36rgwh">CS-36RGWH</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36rgrg">CS-36RGRG</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36ygsv">CS-36YGSV</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36ygbk">CS-36YGBK</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36bkmt">CS-36BKMT</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/cs-36bkwh">CS-36BKWH</a>, <a href="http://knot-designs.com/fs/knot/smallsecond/csog-36svsvyg">CS/OG-36SVSVYG</a>] |
このようにget_title_tag はリストになります。
欲しいのはaタグで囲まれている ” CS… ” のテキスト部分のみなので、for文で1つずつ要素を取り出し、.get_text( ) でテキスト部分のみ抜き取れます(= element_title) 。
element_title を title_list = [ ] に append していきます。
ここでもちゃんと title_list が作成されているか print で確認。
|
1 2 3 4 |
> python main.py ['CS-36SVWH', 'CS-36SVWH1', 'CS-36SVIV', 'CS-36SVNV1', 'CS-36SVBK', 'CS-36RGIV', 'CS-36RGWH', 'CS-36RGRG', 'CS-36YGSV', 'CS-36YGBK', 'CS-36BKMT', 'CS-36BKWH', 'CS/OG-36SVSVYG'] |
うん、上手くできています。
【仕上げ】 画像をダウンロード
|
1 2 3 4 5 6 7 8 9 10 |
for n in range(len(url_list)): image_url = "http://knot-designs.com" + url_list[n] print('画像をダウンロード中 {}...'.format(image_url)) res = requests.get(image_url) res.raise_for_status() image_file = open(os.path.join(folder, os.path.basename(title_list[n]+'.jpg')), 'wb') for chunk in res.iter_content(100000): image_file.write(chunk) image_file.close() |
画像は url_list に格納されている要素数の数だけ保存したいので、for文でリストの要素数をレンジに入れてまわします。
url_list は先ほど get_photo_url( ) 関数で表示してわかっているように、” http://… ” が抜けているので付け足しましょう。
この確認方法は、HP の商品画像の上で DevTools を開き、青く光っているところの src=” /shop/item/… ” の上にカーソル持っていき、右クリック。「 Copy link address 」とあるのでそれを押す。新しくタブを開いてペースト。
すると画像がでてきます。
URL バーで確認すると ” knot-designs.com ” が付け足されているのが確認できます。
os.pathbasename( ) メソッドは保存名を指定できます。
ここで先ほど取得した tittle_list[n] をいれます。title_list はリストなのでインデックス指定を忘れないように。
Requestsオブジェクトを用いてダウンロードしたファイルを保存するときには、iter_content( ) メソッドの値を用いてループします。
forループを用いて画像データのチャンク(最大 100,000 バイト)ごとファイルに書き込んでから、ファイルを閉じます。
これで画像データが test というフォルダに保存されます。
出力はこんな感じです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
> python main.py 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/64_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/65_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/61_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/629_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/59_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/57_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/58_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/422_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/67_thumbnail.jpg... 画像をダウンロード中 http://knot-designs.com/shop/item/knot/picture/goods/66_thumbnail.jpg... ... |
test というフォルダに腕時計画像13枚うまく保存できてたら成功です。
お疲れさまでした。
まとめ
いかがでしょうか。意外と簡単にできるもんです。
ちなみにぼくはこのような腕時計メーカーのHPから商品画像を指定の製品番号の名前をつけて保存するという案件を CrowdWorks で受注しました。
≪HPから300枚程度の画像を「名前を付けて保存」する作業≫
仕事の詳細を見ると、
【概要】
メーカーHPの画像を名前を付けて保存する作業
【依頼内容】
・仕事量:300枚程度
・納期:発注後3~4日程度
慣れれば一枚当たり1分~2分程度でできる作業かと思います。
【必須】
・ブラウザでグーグルクロームが利用できる。
・丁寧に作業して頂ける(保存漏れがないなど)。
その他質問等ありましたら、気軽にお問い合わせください。
という感じでした。
少し細かな流れを確認して、これならスクレイピングでいけそうだなと思って応募しました!(本来は手作業でも構わない案件)
そしたらなんと30人以上申し込みの中から選ばれました!!
業務に活かせる経験として、
“プログラミングができるので、この内容の案件でしたら自動プログラムを作ることができそうです。人の手でやるより漏れなく保存、そしてスピーディーにできそうです。”
という感じで書きました。
これが初めての受注でしたのでとても嬉しかったです。そして契約金額は5,000円!
こんな感じで、ただ参考書を使って勉強するだけではなくて、普段の業務の中から解決したい課題ドリブンでやったほうが楽しいし、技術も身につきます。
ということを少しでも今回の記事で分かっていただけたら!!!





